
कम्प्यूटेशनल जीवविज्ञान और जैव सूचना विज्ञान प्रयोगशाला

कम्प्यूटेशनल बायोलॉजी और बायोइनफॉरमैटिक्स एक तेजी से विकसित होने वाला बहु-विषयक क्षेत्र है। पिछले दशक में बायोमेडिकल डेटा की मात्रा में काफी वृद्धि हुई है। बड़े पैमाने पर जीनोमिक अनुक्रमण के विस्तारित अनुप्रयोग के साथ-साथ, मोबाइल स्वास्थ्य (एमहेल्थ) डेटा और इमेजिंग जैसे अन्य तौर-तरीकों ने भी वृद्धि में योगदान दिया है। साथ ही, कंप्यूटिंग शक्ति और भंडारण क्षमता में वृद्धि जारी रही है, जिससे अब हम अभूतपूर्व क्षमता के साथ जैविक डेटा का खनन और मॉडल बना सकते हैं। हमारी शोध गतिविधियों में जैविक प्रक्रियाओं का कम्प्यूटेशनल मॉडलिंग, बड़े पैमाने पर डेटा सेट का कम्प्यूटेशनल प्रबंधन, डेटाबेस विकास और डेटा-माइनिंग, एल्गोरिदम विकास और उच्च-प्रदर्शन कंप्यूटिंग, साथ ही सांख्यिकीय और गणितीय विश्लेषण शामिल हैं।
प्रयोगशाला से जुड़े संकाय सदस्य

सुष्मिता पॉल
सहायक प्रोफेसर
पंकज यादव
सहायक प्रोफेसरइस विषय के अंतर्गत समूह
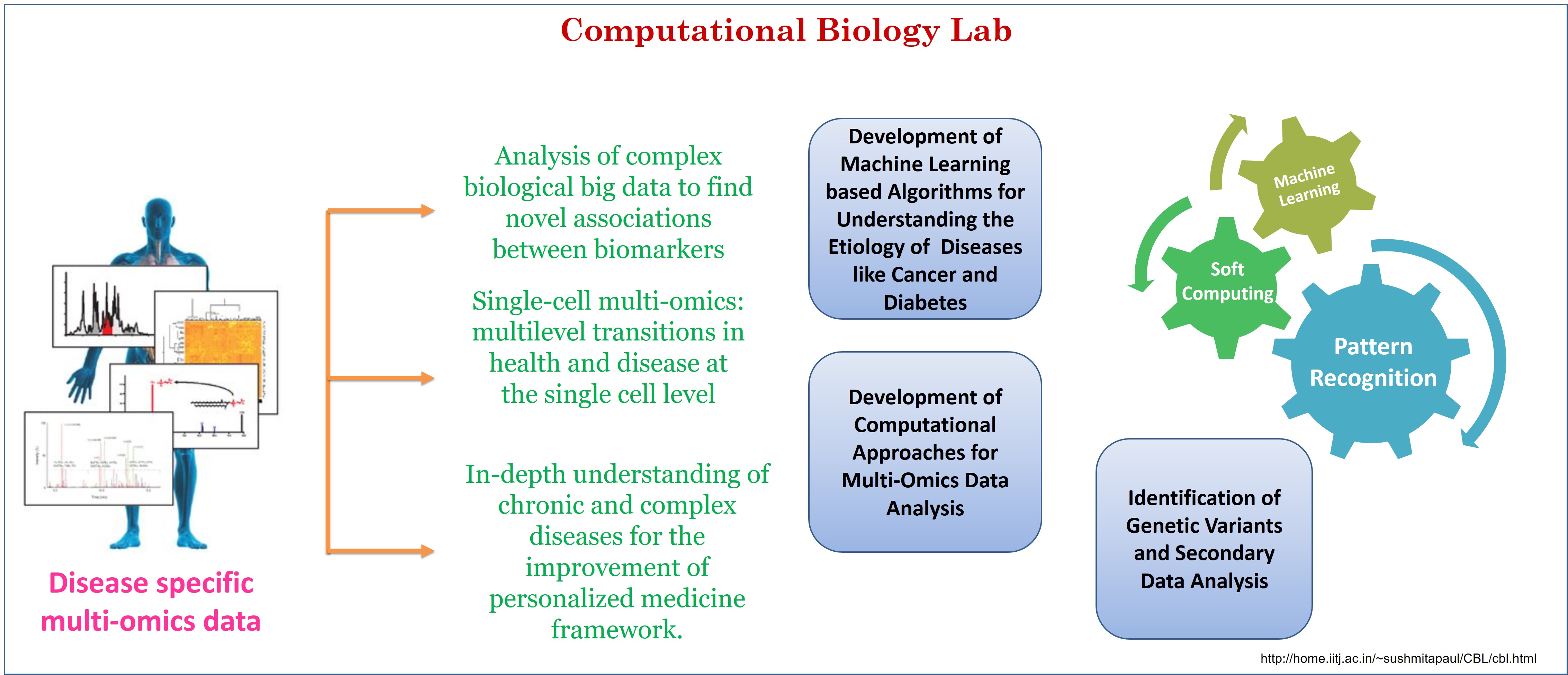
1. कम्प्यूटेशनल बायोलॉजी ग्रुप |
| कम्प्यूटेशनल बायोलॉजी लैब (CBL) की स्थापना कम्प्यूटेशनल बायोलॉजी और बायोइन्फॉर्मेटिक्स के क्षेत्र में मौलिक और उन्नत शोध करने के लिए की गई है। डॉ. सुष्मिता पॉल का शोध समूह मल्टी-ओमिक्स डेटा विश्लेषण, उच्च आयामी जैविक डेटा का विश्लेषण करने के लिए पैटर्न पहचान एल्गोरिदम का विकास, जीनोम भिन्नता का विश्लेषण, बायोइन्फॉर्मेटिक्स उपकरणों का विकास और अनुप्रयोग में शोध करता है। यह समूह मल्टी-ओमिक्स डेटा का उपयोग करके विभिन्न रोगों में miRNA-mRNA मॉड्यूल की पहचान के लिए एल्गोरिदम के विकास में सक्रिय रूप से शामिल है। मल्टी-ओमिक्स डेटा विश्लेषण से संबंधित एक अन्य महत्वपूर्ण चुनौती कैंसर उपप्रकार का वर्गीकरण है। इस संबंध में, समूह ने कैंसर के नमूनों को उनके संबंधित उप-प्रकारों में प्रभावी रूप से वर्गीकृत करने के लिए एक एल्गोरिदम विकसित किया है। यह समूह भारतीय आबादी में जीनोमिक वेरिएंट के कार्यात्मक एनोटेशन, आनुवंशिक वेरिएंट के आधार पर भारतीय आबादी के उप-समूहीकरण में भी शामिल है। समूह रोगी की बायोप्सी से प्राप्त ट्यूमर स्फेरॉयड के आधार पर उपचार के लिए रोगी के परिणाम की भविष्यवाणी करने के लिए एक एआई आधारित ढांचे के विकास पर भी ध्यान केंद्रित कर रहा है। समूह ने जीन अभिव्यक्ति डेटा और प्रोटीन-प्रोटीन इंटरैक्शन नेटवर्क डेटा को विवेकपूर्ण तरीके से एकीकृत करके टाइप II मधुमेह जीन की पहचान करने के लिए कई एल्गोरिदम/ढांचे भी विकसित किए हैं। सीबी लैब ने ओल्ज़टीन, पोलैंड, 2017 में बायोमेडिकल डेटा विश्लेषण में हालिया प्रगति पर एक अंतर्राष्ट्रीय कार्यशाला भी आयोजित की (http://ijcrs2017.uwm.edu.pl/?page_id=190)। 2019 में, लैब ने आईआईटी जोधपुर में कम्प्यूटेशनल बायोलॉजी और बायोइनफॉरमैटिक्स पर एक राष्ट्रीय स्तर की कार्यशाला आयोजित की (http://home.iitj.ac.in/~sushmitapaul/Workshop2019/) |
|
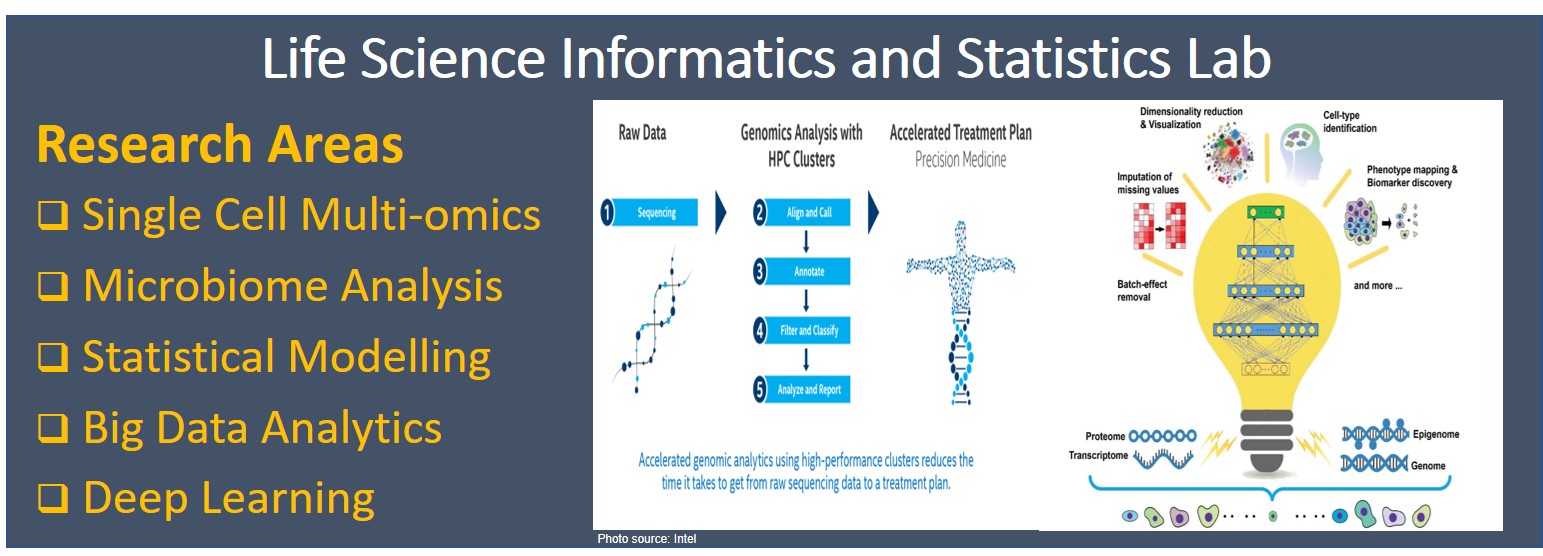
2. जीवन विज्ञान सूचना विज्ञान और सांख्यिकी समूह
|
प्रौद्योगिकियों में हाल की प्रगति ने शोधकर्ताओं के लिए भारी मात्रा में जैविक और नैदानिक डेटा उत्पन्न किया है। डेटा का यह खजाना ऐसी चुनौतियाँ पेश करता है जिनका पहले कभी सामना नहीं किया गया। इनका मूल उद्देश्य यह समझना है कि स्वास्थ्य और बीमारी में जीवित प्रणालियों के कार्य के बारे में नए ज्ञान की खोज के लिए विशाल जैविक डेटा सेट का सबसे अच्छा विश्लेषण कैसे किया जाता है, और इस ज्ञान का उपयोग बेहतर, अधिक किफायती स्वास्थ्य सेवा प्रदान करने के लिए कैसे किया जा सकता है। इस उद्देश्य के लिए, डेटा सेट की इतनी बड़ी मात्रा को प्रबंधित करने और उसका विश्लेषण करने के लिए परिष्कृत उपकरणों की आवश्यकता है। यह शोध समूह जैविक और नैदानिक डेटा से सांख्यिकीय रूप से मान्य निष्कर्ष निकालने के लिए उन्नत सांख्यिकीय और कम्प्यूटेशनल विधियों को विकसित करने के लिए समर्पित है। हम बड़े पैमाने पर सांख्यिकीय मॉडलिंग और OMICS डेटा की कई परतों को एकीकृत करके अंतर-व्यक्तिगत अंतरों का अध्ययन करते हैं। |
प्रयोगशाला द्वारा वर्तमान में कार्यान्वित की जा रही परियोजनाएँ |
1. गर्भाशय ग्रीवा के कैंसर के एटियलजि को समझने के लिए miRNA और mRNA अभिव्यक्ति डेटा का विश्लेषण (डॉ. सुष्मिता पॉल) |
भारत में कैंसर मृत्यु का दूसरा सबसे आम कारण है। भारत में किसी भी अन्य देश की तुलना में अधिक महिलाएँ गर्भाशय ग्रीवा के कैंसर से मरती हैं। कैंसर की चुनौतियों का समाधान करने के लिए अंतरराष्ट्रीय स्तर पर कुछ परियोजनाएँ शुरू की गई हैं जैसे कि कैंसर जीनोम एटलस (TCGA) और अंतर्राष्ट्रीय कैंसर जीनोम कंसोर्टियम (ICGC)। ये परियोजनाएँ जीनोमिक डेटा उत्पन्न करने के लिए उन्नत जीनोमिक तकनीकों का उपयोग करती हैं जिनका उपयोग सांख्यिकीय और जैविक रूप से महत्वपूर्ण निष्कर्ष निकालने के लिए किया जाता है। हालाँकि TCGA के शोध नेटवर्क द्वारा कई महत्वपूर्ण खोजें की गई हैं, फिर भी नए तरीकों को लागू करने के अवसर मौजूद हैं, जिससे महत्वपूर्ण नैदानिक चिह्नों और नए जैविक मार्गों को स्पष्ट किया जा सके। परियोजना का मुख्य उद्देश्य मल्टीमॉडल ओमिक्स डेटा की भूमिका को समझने के लिए कुछ कम्प्यूटेशनल दृष्टिकोण विकसित करना है, अर्थात गर्भाशय ग्रीवा के कैंसर की उत्पत्ति और प्रगति के लिए जिम्मेदार miRNA और mRNA। इस संबंध में, एक अप्रशिक्षित क्लस्टरिंग एल्गोरिदम विकसित किया जाएगा जो बिना लेबल वाले डेटा के लिए कैंसर के आणविक उपप्रकारों को चिह्नित करने में मदद कर सकता है। सहसंबद्ध बायोमार्करों के समूहों की पहचान के लिए एक पर्यवेक्षित क्लस्टरिंग विधि विकसित की जाएगी जो नमूना श्रेणियों के साथ दृढ़ता से जुड़े हुए हैं। विभिन्न प्रकार के बायोमार्करों को समूहीकृत करने के लिए एक साथ सुविधा चयन और क्लस्टरिंग एल्गोरिदम विकसित किए जाएंगे जो नमूनों या नैदानिक परिणामों के एक उपसमूह में समान व्यवहार प्रदर्शित करते हैं। अंत में, प्राप्त परिणामों के जैविक महत्व का अध्ययन जीन ऑन्कोलॉजी, नेटवर्क विश्लेषण और गीले प्रयोगशाला प्रयोगों के साथ-साथ साहित्य में उपलब्ध जैविक जानकारी का उपयोग करके किया जाएगा। |
| 2. टाइप II मधुमेह के रोग जीन की पहचान के लिए एकीकृत दृष्टिकोण (डॉ. सुष्मिता पॉल) |
| वर्तमान में, भारत मधुमेह को एक गंभीर महामारी की स्थिति के रूप में देख रहा है। लगभग 62 मिलियन मधुमेह रोगी पहले से ही इस बीमारी से पीड़ित हैं। एक सर्वेक्षण में पाया गया कि भारत (31.7 मिलियन) में मधुमेह के सबसे अधिक मामले हैं, उसके बाद चीन (20.8 मिलियन) और अमेरिका (17.7 मिलियन) क्रमशः दूसरे और तीसरे स्थान पर हैं। 2030 तक दुनिया भर में मधुमेह के रोगियों की संख्या दोगुनी हो जाएगी और भारत में सबसे अधिक मामले होंगे। यदि रोग के कारणों को समझने के लिए तत्काल कार्रवाई नहीं की गई तो भारत को संभावित बोझ का सामना करना पड़ सकता है। मधुमेह के प्रसार के लिए कई आनुवंशिक/एपिजेनेटिक कारक जिम्मेदार हैं और रोग के जीव विज्ञान को समझने के लिए उन कारकों की पहचान करना महत्वपूर्ण है। रोग की घटनाओं को समझने के लिए पहचाने गए आनुवंशिक कारकों के बीच परस्पर क्रिया का भी अध्ययन करने की आवश्यकता है। मधुमेह के संभावित रोग जीन का उपयोग इसके खिलाफ दवाओं के विकास के लिए लक्ष्य के रूप में किया जा सकता है। इसके अलावा, रोग के जीन का उपयोग निदान उपकरणों के विकास के लिए किया जा सकता है जो रोग की संभावना को समझने में मदद कर सकते हैं। हालाँकि, प्रयोगात्मक रूप से संभावित रोग जीन की पहचान करना बहुत महंगा है और साथ ही इसमें बहुत समय भी लगता है। इस समस्या को दूर करने के लिए संभावित रोग जीन की सूची की पहचान करने के लिए सांख्यिकीय और कम्प्यूटेशनल विधियों का उपयोग किया जा सकता है। पूर्वानुमानित रोग जीन न केवल प्रयोग की लागत को कम करेंगे बल्कि समय की आवश्यकता भी कम हो जाएगी। पूर्वानुमानित जीन के नेटवर्क विश्लेषण से रोग के तंत्र को समझने में मदद मिलेगी। |
| 3. जीनोमइंडिया: भारतीयों में आनुवंशिक भिन्नता को सूचीबद्ध करना (डॉ. सुष्मिता पॉल) |
| व्यक्तियों में आनुवंशिक भिन्नताएँ अक्सर जनसंख्या-विशिष्ट होती हैं और उन्हें बीमारियों के लिए प्रवृत्त कर सकती हैं और कुछ दवाओं के प्रति उनकी प्रतिक्रिया या प्रतिकूल प्रभाव निर्धारित कर सकती हैं। इसने कई देशों को जनसंख्या-विशिष्ट अनुक्रमण परियोजनाओं को लागू करने के लिए प्रेरित किया है। विविध जातीय समूहों वाली एक बड़ी आबादी होने के बावजूद, भारत में आनुवंशिक भिन्नताओं की एक व्यापक सूची का अभाव है। भारत में, हमारे पास आनुवंशिक भिन्नताओं की संदर्भ सूची नहीं है, जो मोनोजेनिक विकारों के लिए कारण भिन्नताओं की पहचान करना कठिन और गलत बनाता है। वर्तमान में, भारत के पास कोई देश-विशिष्ट जीनोम वाइड चिप भी नहीं है जो बड़े पैमाने पर व्यापक आनुवंशिक अध्ययन को वहनीय बना सके। इसके लिए भारत में राष्ट्रीय स्तर पर प्रयास की आवश्यकता है ताकि देश भर में विविध भौगोलिक क्षेत्रों और जातीयताओं से बड़ी संख्या में व्यक्तियों की संपूर्ण जीनोम अनुक्रमण द्वारा इसकी विविध आबादी की आनुवंशिक विविधताओं को सूचीबद्ध किया जा सके। इस अध्ययन के परिणाम अन्य दक्षिण एशियाई देशों के लिए भी उपयोगी होंगे, क्योंकि भारतीय आनुवंशिकी पड़ोसी दक्षिण एशियाई देशों के लिए प्रासंगिक है। यह विश्वव्यापी मानव आनुवंशिकी अनुसंधान समुदाय के लिए ज्ञान और सूचना का एक बहुत बड़ा लाभ होगा क्योंकि बड़े पैमाने पर व्यापक आनुवंशिक अध्ययन पारंपरिक रूप से सामान्य रूप से यूरोपीय आबादी के आसपास केंद्रित रहे हैं, और हाल ही में अफ्रीकी और हिस्पैनिक आबादी के लिए ही शुरुआत हुई है। |
| 4. मानव स्वास्थ्य के लिए एक एआई प्लेटफॉर्म का विकास (डॉ. सुष्मिता पॉल, सह-पीआई) |
| रोगी बायोप्सी से प्राप्त ट्यूमर स्फेरॉयड के आधार पर उपचार के लिए रोगी के परिणाम की भविष्यवाणी करने के लिए एक एआई आधारित ढांचा विकसित करना। सिलिकोसिस और तपेदिक का पता लगाने और विभेदन के लिए एक स्वचालित छाती रेडियोग्राफ आधारित नैदानिक उपकरण विकसित करना। |
| 5. केवल केस-ओनली दृष्टिकोण के बाद जटिल रोगों के संबंध में जीनोम-वाइड जीन-पर्यावरण इंटरैक्शन की जांच (डॉ. पंकज यादव) |
| गैर-संचारी रोग (एनसीडी), विशेष रूप से कैंसर, पुरानी श्वसन संबंधी बीमारियाँ और मधुमेह, वैश्विक स्तर पर मृत्यु दर के प्रमुख कारण हैं। वर्ष 2012 में वैश्विक स्तर पर हुई 56 मिलियन मौतों में से 38 मिलियन (लगभग 68%) एनसीडी के कारण हुई थीं और यह संख्या 2030 तक 52 मिलियन तक बढ़ने का अनुमान है। भारत में एनसीडी से होने वाली मौतों की संख्या 1998 में लगभग 4.5 मिलियन से बढ़कर 2020 तक लगभग दोगुनी होकर 8 मिलियन होने का अनुमान है। इस परियोजना का उद्देश्य विभिन्न एनसीडी के संबंध में जीनोम-व्यापी स्तर पर अंतर्निहित जीन-पर्यावरण अंतःक्रिया का पता लगाने के लिए उपलब्ध आंकड़ों पर केवल मामला-आधारित दृष्टिकोण को लागू करना है। |
उपलब्ध मुख्य उपकरण |
| सर्वर |
| वर्कस्टेशन |
| डेस्कटॉप |
सॉफ्टवेयर विकसित किया गया |
| आरएफसीएम3 ((http://home.iitj.ac.in/~sushmitapaul/CBL/softwares.html) |











